Are longer context windows all you need?
Thoughts on AI Codegen
Lately I’ve been trying to understand how to evaluate AI for software engineering (in a broad sense) and what the capability ramp will look like.
Zuck says Meta will automate mid-level engineers by this year. Salesforce has frozen hiring for engineers. Everybody’s building something here.
I’ve spent a lot of time playing with different AI coding frameworks and think I see 1) where we’re at today, and 2) where we’re going.
What has been built?
Public coding frameworks are nearly all general purpose tools designed to be useful in a wide range of environments. Aider, for example, benchmarks on a ‘polyglot’ range of languages. This strategy is interesting, there’s a very long tail of how people code, and trying to be useful in every coding paradigm or language is hard. This is a place where OSS tools might do well because there’s a very long tail of use cases / stacks to be supported, and collaboration can help iron out the edge cases.
On the lightest weight end, you have manually pasting into a chat interface and pasting back to an IDE. Claude Artifacts and ChatGPT code interpreter are a step above that, with the ability to run a small subset of code and see the outputs. However, it’s not particularly easy for the user to make changes to the code inline, only via prompting.
Perhaps a stylized timeline of the tools can be useful here.
IN THE BEGINNING, there was autocomplete, popularized by Github Copilot. Autocomplete operates on the surrounding code and attempts to find the most likely code snippet to insert.

THEN, there was chat, popularized by Cursor. This is a similar experience to ChatGPT or Claude, but instead of copy-pasting code from the IDE, chat features can add files or code directly from the IDE. Chat is more freeform and involves back and forth with the model, which can solve more open-ended problems than purely autocomplete. Over time, tools got better at doing in-line find/replace.

NOW, there are ‘agents.’ These agents attempt to write code, see the output from checks e.g. lint or running tests, then iterate on that feedback. The focus is on directly making changes that solve the user’s request.
There are SO many competing approaches here. Engineers really like writing code and building devtools, who would have known? An non-exhaustive categorization and list of features and design patterns I’ve seen:
Mechanisms to manage context
Knowledge graph via AST parsing (see Aider’s writeup)
Slash commands to add files (see Zed, Aider)
Model Context Protocol integration (eg Cline) and looking at file names
Mechanisms to plan
Architect mode (reasoning model a la O1 describes how to solve the problem, traditional model writes actual code)
Multiple personas for agents (see CodeR, Aide, MarsCode) with specialized debuggers and reproducers etc.
“Agentless”: localization, repair, and patch validation only
Search + MCTS (swe-search, moatless-tree-search)
Mechanisms to test and iterate
Browser integration for testing (Cline uses Claude Computer Use, Devin has their own browser)
Local testing integration (most tools offer CLI access, also see mpc-local-dev)
Mechanisms to customize models
Interaction mechanisms
Some things I haven’t seen yet but would like to:
Integrated best-of-n / parallel calls. Possible with Deepseek and other less rate-limited providers.
Deterministic refactoring with LSP tools. Think everything that Jetbrains builds specifically into their IDE.
Autodocument code so that it’s easier to pick the right file / function. On a similar vein, note findings so that it’s easier to make future changes.
The sheer quantity of apps and design patterns is cool to see and also speaking to how diverse software engineering is today. I think open source tools will remain very competitive here: people like building these tools, we’re all using the same models, and it’s easy to copy features.
How can we categorize the frameworks?
One rough way we can bucket these code gen solutions is along how much discretion and autonomy they allow AI agents.
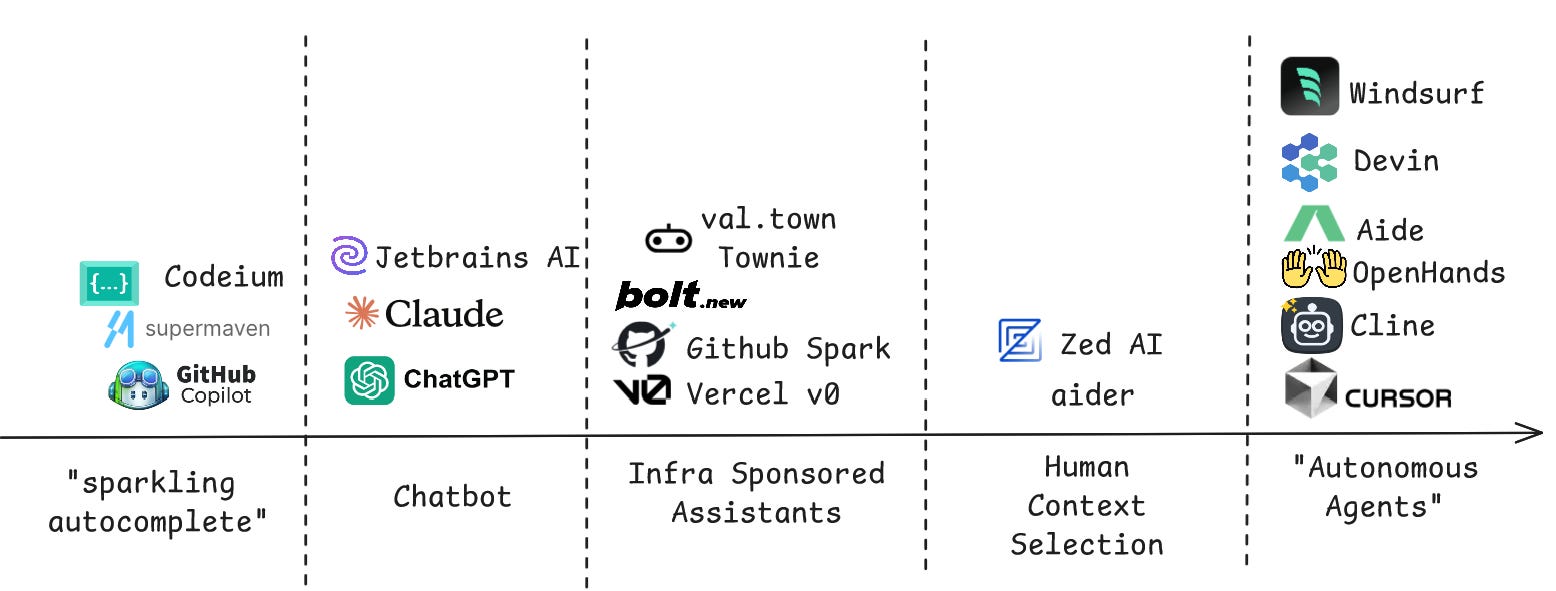
These are very rough categorizations and of course many apps encompass multiple categories, e.g. Cursor has their own autocomplete and chat interface too. I have exercised my judgment to choose based on how most people use the apps. As we’ll see below, I also don’t think ‘more autonomous’ is always better!
One special category is “infra sponsored assistants.” These tools write code that is designed to be run in a very specific runtime and serve as top-of-funnel marketing for the platform. They’re well-suited for small 0-1 projects and for newbies: smaller decision space, easier to use. All of these platforms so far target NodeJS runtimes, so that the apps can be interacted with in-browser. There’s been huge uptake: Bolt.new hit $20M ARR and 200k new weekly users within a few months, mainly via people that are new to coding. Today I haven’t seen much pricing pressure here yet - the markets are super new and the UX premium is super valuable - but in the long-term I’d expect these to drop in price a lot. I expect every cloud provider to offer a tool like this; Azure announced building towards their version yesterday.
Another category to call out is the ‘human context selection’ bucket. One thing I found annoying about Aider at first was that I needed to manually add the files that I wanted in context. However, after trying other agents that try to index the codebase and find the most relevant context, I found myself grateful for Aider’s manual selection! The search and retrieval for relevant code was lacking, and giving models bad information is much worse than giving them no information. This is kind of like a human: you need to understand a codebase before you can be effective in it.
This context problem might be the biggest bottleneck to AI coding now.
How can we evaluate AI coders?
One way we evaluate human engineers is on the dimension of ‘scope.’ More senior engineers are expected to cover more technical and organizational scope.
Below is a rough leveling chart, for human engineers, courtesy of my friend Claude.
Today’s models and frameworks are probably somewhere between junior and mid-level now. Zuck thinks Meta will automate mid-level engineers this year, which roughly lines up with this timeline; I will hold the jokes about Meta engineers though. I would argue this is somewhat easy at Meta because they have good infrastructure and internal SDK’s and high risk tolerance for breaking things, so the process of building a new feature is already mostly formulaic and automatable.
We could come up with a similar leveling chart for AI engineers.
In this case, models need to get better at reasoning about any particular change, but they also notably need to utilize longer context. If you dropped a great human coder like John Carmack into a new codebase and didn’t let them look at the right files or business docs, they would also write something unexpected.
How do we scale context?
One simple way you can solve imperfect search over larger codebases is to just put everything into context. A medium size project I built ended up with roughly 100k tokens, which is a reasonable guess of order of magnitude for necessary context. However, if you include the code/docs for external dependencies, the relevant token count would increase significantly. Similarly, to help a model reason about ambiguous business tasks, we could feed it a long history of internal corporate decisions as well as competitive analysis to allow it to reason and plan like a human might. Another way is to allow reasoning models to reason for longer, e.g. the ‘high effort’ mode in o1, which utilizes more context to try and get to a better answer.
Long context requires both the memory to hold previous tokens as well as making the model well-trained enough to use the context effectively. Both dimensions are very challenging to scale and evaluate.
On scaling, the only commercially available 1M context model is Gemini, which doubles its pricing for long context input; the next longest is the OpenAI o1 family, which supports 200k and Claude 3. Claude was trained to 1M context window, but Anthropic probably doesn’t have enough GPUs or demand to serve at that full context. As far as I can tell other models cap out at 128k, including GPT-4o, Deepseek v3, Llama 3, and so on. On the hardware side, most folks use something like Ring Attention to scale up efficiently and distribute the computation over a large cluster of networked GPUs. Theoretically this is fairly straightforward to scale, you ‘just’ connect more boxes, but larger clusters also increase the likelihood of bad nodes and are overall much more expensive to run.
Using long context effectively is also difficult. At training time, this requires a lot of long context data and memory to train. Commonly, teams will do most of the training at a lower context length and higher batch size, and cool down with the largest context length at lower batch size. For example, DeepSeek pretrained at 4k context, then progressively trained 1000 steps of 32k and 128k context. It’s also very difficult and expensive for humans to carefully reason and evaluate over lots of context too. Simple benchmarks like ‘needle in a haystack’ don’t necessarily show reasoning over all the context and models are smart enough to detect contrived tasks:

As currently formulated, the ‘memory wall’ is the bottleneck for more intelligence. As a customer, you can’t spend more money to get infinitely more tokens, because networking enough servers and serving at small enough batch size to support those lengths would be uneconomical for the provider.
All that being said - I expect the hardware and modeling constraints to fall eventually. Humans are very good at identifying and solving bottlenecks. The new Blackwell NVL72 clusters network 72 GPU’s together with super fast NVLink, and the new GB300 GPU’s provide 288GB of memory too. Perhaps o3’s API price will be 10x previous prices, and we will just pay it anyways.
Let’s have some fun before we’re all in the bread lines together.